https://mp.weixin.qq.com/s/DHTPSfmWTZpdTmlytzLz1g
redis优势
- Redis支持服务器端的数据操作:Redis相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached里,你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么Redis会是不错的选择。
- 集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是redis目前是原生支持cluster模式的,redis官方就是支持redis cluster集群模式的,比memcached来说要更好。
在项目中缓存是如何使用的?为啥在项目里要用缓存呢?
高性能:假设这么个场景,你有个操作,一个请求过来,吭哧吭哧你各种乱七八糟操作mysql,半天查出来一个结果,耗时600ms。但是这个结果可能接下来几个小时都不会变了,或者变了也可以不用立即反馈给用户。那么此时咋办?
缓存啊,折腾600ms查出来的结果,扔缓存里,一个key对应一个value,下次再有人查,别走mysql折腾600ms了。直接从缓存里,通过一个key查出来一个value,2ms搞定。性能提升300倍。
这就是所谓的高性能。
高并发
mysql这么重的数据库,压根儿设计不是让你玩儿高并发的,虽然也可以玩儿,但是天然支持不好。mysql单机支撑到2000qps也开始容易报警了。
所以要是你有个系统,高峰期一秒钟过来的请求有1万,那一个mysql单机绝对会死掉。你这个时候就只能上缓存,把很多数据放缓存,别放mysql。缓存功能简单,说白了就是key-value式操作,单机支撑的并发量轻松一秒几万十几万,支撑高并发so easy。单机承载并发量是mysql单机的几十倍。
redis数据类型
- string:这是最基本的类型了,没啥可说的,就是普通的set和get,做简单的kv缓存
- hash:这个是类似map的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在redis里,然后每次读写缓存的时候,可以就操作hash里的某个字段。
key=150
value={
“id”: 150,
“name”: “zhangsan”,
“age”: 20
}hash类的数据结构,主要是用来存放一些对象,把一些简单的对象给缓存起来,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值
value={
“id”: 150,
“name”: “zhangsan”,
“age”: 21
}- list:有序列表,这个是可以玩儿出很多花样的
比如可以通过list存储一些列表型的数据结构,类似粉丝列表了、文章的评论列表了之类的东西
比如可以通过lrange命令,就是从某个元素开始读取多少个元素,可以基于list实现分页查询,这个很棒的一个功能,基于redis实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走
比如可以搞个简单的消息队列,从list头怼进去,从list尾巴那里弄出来
- set:无序集合,自动去重
直接基于set将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于jvm内存里的HashSet进行去重,但是如果你的某个系统部署在多台机器上呢?
得基于redis进行全局的set去重
可以基于set玩儿交集、并集、差集的操作,比如交集吧,可以把两个人的粉丝列表整一个交集,看看俩人的共同好友是谁?对吧
把两个大v的粉丝都放在两个set中,对两个set做交集
- sorted set:
排序的set,去重但是可以排序,写进去的时候给一个分数,自动根据分数排序,这个可以玩儿很多的花样,最大的特点是有个分数可以自定义排序规则
比如说你要是想根据时间对数据排序,那么可以写入进去的时候用某个时间作为分数,人家自动给你按照时间排序了
排行榜:将每个用户以及其对应的什么分数写入进去,zadd board score username,接着zrevrange board 0 99,就可以获取排名前100的用户;zrank board username,可以看到用户在排行榜里的排名
redis的过期策略
- 设置过期时间:我们set key的时候,都可以给一个expire time,就是过期时间,指定这个key比如说只能存活1个小时?10分钟?这个很有用,我们自己可以指定缓存到期就失效。
定期删除+惰性删除
所谓定期删除,指的是redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。假设redis里放了10万个key,都设置了过期时间,你每隔几百毫秒,就检查10万个key,那redis基本上就死了,cpu负载会很高的,消耗在你的检查过期key上了。注意,这里可不是每隔100ms就遍历所有的设置过期时间的key,那样就是一场性能上的灾难。实际上redis是每隔100ms随机抽取一些key来检查和删除的。
但是问题是,定期删除可能会导致很多过期key到了时间并没有被删除掉,那咋整呢?所以就是惰性删除了。这就是说,在你获取某个key的时候,redis会检查一下 ,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
内存淘汰机制
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的key给干掉啊
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key(这个一般不太合适)
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
redis单线程模型
为啥redis单线程模型也能效率这么高?
- 纯内存操作
- 核心是基于非阻塞的IO多路复用机制
- 单线程反而避免了多线程的频繁上下文切换问题
io多路复用
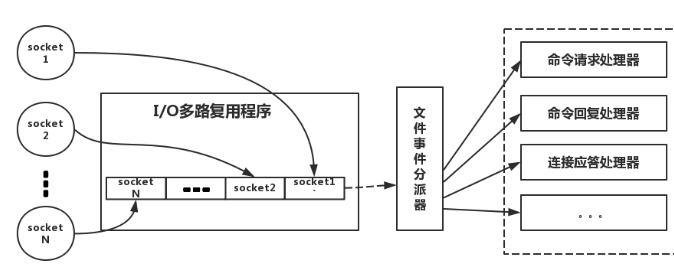
怎么保证redis挂掉之后再重启数据可以进行恢复?
RDB持久化机制,对redis中的数据执行周期性的持久化
AOF机制对每条写入命令作为日志,以append-only的模式写入一个日志文件中,在redis重启的时候,可以通过回放AOF日志中的写入指令来重新构建整个数据集。
如果我们想要redis仅仅作为纯内存的缓存来用,那么可以禁止RDB和AOF所有的持久化机制。
通过RDB或AOF,都可以将redis内存中的数据给持久化到磁盘上面来,然后可以将这些数据备份到别的地方去,比如说阿里云,云服务。
如果redis挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上拷贝回来之前的数据,放到指定的目录中,然后重新启动redis,redis就会自动根据持久化数据文件中的数据,去恢复内存中的数据,继续对外提供服务。
如果同时使用RDB和AOF两种持久化机制,那么在redis重启的时候,会使用AOF来重新构建数据,因为AOF中的数据更加完整。
RDB持久化机制的优点?
- RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中redis的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说Amazon的S3云服务上去,在国内可以是阿里云的ODPS分布式存储上,以预定好的备份策略来定期备份redis中的数据。
- RDB对redis对外提供的读写服务,影响非常小,可以让redis保持高性能,因为redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可。
- 相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复redis进程,更加快速。
RDB持久化机制的缺点?
- 如果想要在redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说,RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据
- RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。
AOF持久化机制的优点?
- AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据
- AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。
- AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在rewrite log的时候,会对其中的指导进行压缩,创建出一份需要恢复数据的最小日志出来。再创建新日志文件的时候,老的日志文件还是照常写入。当新的merge后的日志文件ready的时候,再交换新老日志文件即可。
- AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据。
AOF持久化机制的缺点?
- 对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
- AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
- 以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似AOF这种较为复杂的基于命令日志/merge/回放的方式,比基于RDB每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有bug。不过AOF就是为了避免rewrite过程导致的bug,因此每次rewrite并不是基于旧的指令日志进行merge的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
RDB和AOF到底该如何选择?
- 不要仅仅使用RDB,因为那样会导致你丢失很多数据
- 也不要仅仅使用AOF,因为那样有两个问题,第一,你通过AOF做冷备,没有RDB做冷备,来的恢复速度更快; 第二,RDB每次简单粗暴生成数据快照,更加健壮,可以避免AOF这种复杂的备份和恢复机制的bug
- 综合使用AOF和RDB两种持久化机制,用AOF来保证数据不丢失,作为数据恢复的第一选择; 用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复
哨兵模式
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
sentinel monitor <master-name> <ip> <redis-port> <quorum>
#告诉sentinel去监听地址为ip:port的一个master,这里的master-name可以自定义,quorum是一个数字,指明当有多少个sentinel认为一个master失效时,master才算真正失效
sentinel auth-pass <master-name> <password>
#设置连接master和slave时的密码,注意的是sentinel不能分别为master和slave设置不同的密码,因此master和slave的密码应该设置相同。
故障切换(failover)的过程
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
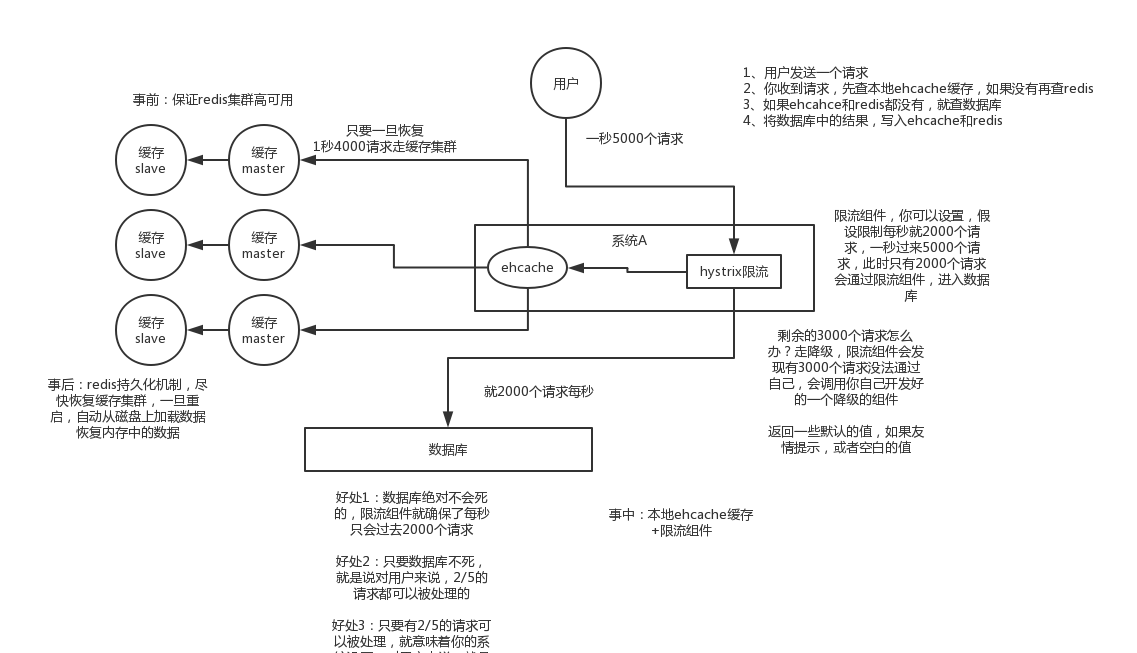
缓冲雪崩
一堆数据,同时失效
缓存穿透
一个数据,或者热点数据,失效
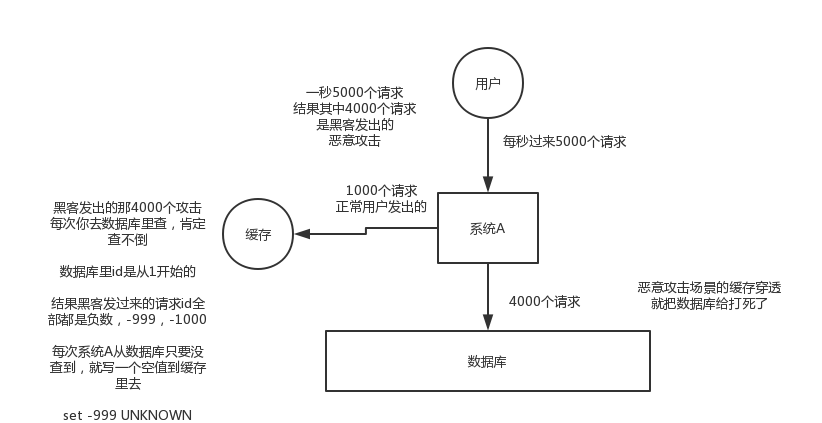
缓存击穿
没有数据,直接打库
sortset为什么使用的是跳表,而不使用红黑树?
其中插入删除,删除,查找以及迭代输出时间复杂度红黑树和跳表的时间复杂度是一样的。
- 跳表在区间查询的时候效率是高于红黑树的,跳表进行查找O(logn)的时间复杂度定位到区间的起点,然后在原始链表往后遍历就可以了 ,其他插入和单个条件查询,更新两者的复杂度都是相同的O(logn)
- 跳表的代码实现相对于红黑树更容易实现,
- 跳表更加灵活,他可以通过改变索引构建策略,有效平衡执行效率和内存消耗。(红黑树的平衡是通过左旋转和有旋转来进行平衡)



