IO模型
BIO:线程发起IO请求,不管内核是否准备好IO操作,从发起请求起,线程一直阻塞,直到操作完成。如下图:
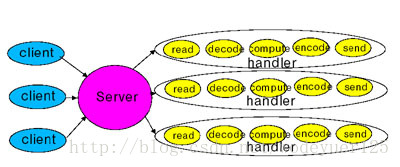
NIO(reactor模型):线程发起IO请求,立即返回;内核在做好IO操作的准备之后,通过调用注册的回调函数通知线程做IO操作,线程开始阻塞,直到操作完成。如下图:
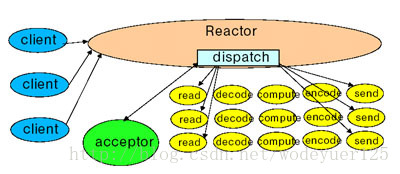
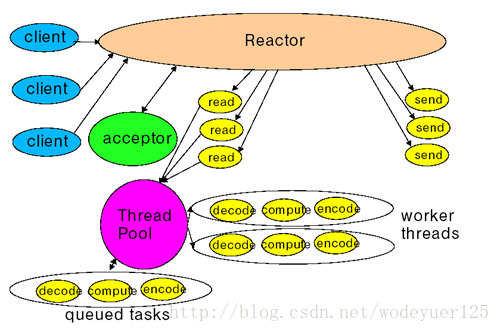
AIO(proactor模型):线程发起IO请求,立即返回;内存做好IO操作的准备之后,做IO操作,直到操作完成或者失败,通过调用注册的回调函数通知线程做IO操作完成或者失败。如下图:
- BIO (Blocking I/O):同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。这里使用那个经典的烧开水例子,这里假设一个烧开水的场景,有一排水壶在烧开水,BIO的工作模式就是, 叫一个线程停留在一个水壶那,直到这个水壶烧开,才去处理下一个水壶。但是实际上线程在等待水壶烧开的时间段什么都没有做。
因为BIO模型下一个线程同时只能做一个工作,如果线程在执行过程中依赖于需要等待的资源,那么该线程会长期处于阻塞状态,我们知道在整个操作系统中,线程是系统执行的基本单位,在BIO模型下的线程 阻塞就会导致系统线程的切换,从而对整个系统性能造成一定的影响。当然如果我们只需要创建少量可控的线程,那么采用BIO模型也是很好的选择,但如果在需要考虑高并发的web或者tcp服务器中采用BIO模型就无法应对了,如果系统开辟成千上万的线程,那么CPU的执行时机都会浪费在线程的切换中,使得线程的执行效率大大降低。此外,关于线程这里说一句题外话,在系统开发中线程的生命周期一定要准确控制,在需要一定规模并发的情形下,尽量使用线程池来确保线程创建数目在一个合理的范围之内,切莫编写线程数量创建上限的代码。
- NIO (New I/O):同时支持阻塞与非阻塞模式,但这里我们以其同步非阻塞I/O模式来说明,那么什么叫做同步非阻塞?如果还拿烧开水来说,NIO的做法是叫一个线程不断的轮询每个水壶的状态,看看是否有水壶的状态发生了改变,从而进行下一步的操作。
关于NIO,国内有很多技术博客将英文翻译成No-Blocking I/O,非阻塞I/O模型 ,当然这样就与BIO形成了鲜明的特性对比。NIO本身是基于事件驱动的思想来实现的,其目的就是解决BIO的大并发问题,在BIO模型中,如果需要并发处理多个I/O请求,那就需要多线程来支持,NIO使用了多路复用器机制,以socket使用来说,多路复用器通过不断轮询各个连接的状态,只有在socket有流可读或者可写时,应用程序才需要去处理它,在线程的使用上,就不需要一个连接就必须使用一个处理线程了,而是只是有效请求时(确实需要进行I/O处理时),才会使用一个线程去处理,这样就避免了BIO模型下大量线程处于阻塞等待状态的情景。
- AIO ( Asynchronous I/O):异步非阻塞I/O模型。异步非阻塞与同步非阻塞的区别在哪里?异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知我水烧开了。
NIO需要使用者线程不停的轮询IO对象,来确定是否有数据准备好可以读了,而AIO则是在数据准备好之后,才会通知数据使用者,这样使用者就不需要不停地轮询了。当然AIO的异步特性并不是Java实现的伪异步,而是使用了系统底层API的支持,在Unix系统下,采用了epoll IO模型,而windows便是使用了IOCP模型。
RPC
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。比如两个不同的服务 A、B 部署在两台不同的机器上,那么服务 A 如果想要调用服务 B 中的某个方法该怎么办呢?使用 HTTP请求 当然可以,但是可能会比较慢而且一些优化做的并不好。 RPC 的出现就是为了解决这个问题。
dubb支持的序列化
- dubbo 协议
- rmi 协议
- hessian 协议
- http 协议
- webservice
rpc原理
- 服务消费方(client)调用以本地调用方式调用服务;
- client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
- client stub找到服务地址,并将消息发送到服务端;
- server stub收到消息后进行解码;
- server stub根据解码结果调用本地的服务;
- 本地服务执行并将结果返回给server stub;
- server stub将返回结果打包成消息并发送至消费方;
- client stub接收到消息,并进行解码;
- 服务消费方得到最终结果。
dubbo优势
- 负载均衡——同一个服务部署在不同的机器时该调用那一台机器上的服务。
- 服务调用链路生成——随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
- 服务访问压力以及时长统计、资源调度和治理——基于访问压力实时管理集群容量,提高集群利用率。
- 服务降级——某个服务挂掉之后调用备用服务。
负载均衡策略
Random LoadBalance(默认,基于权重的随机负载均衡机制)
随机,按权重设置随机概率。在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
RoundRobin LoadBalance(不推荐,基于权重的轮询负载均衡机制)
轮循,按公约后的权重设置轮循比率。存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
LeastActive LoadBalance
最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHash LoadBalance
一致性 Hash,相同参数的请求总是发到同一提供者。(如果你需要的不是随机负载均衡,是要一类请求都到一个节点,那就走这个一致性hash策略。)当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
zookeeper宕机与dubbo直连的情况
在实际生产中,假如zookeeper注册中心宕掉,一段时间内服务消费方还是能够调用提供方的服务的,实际上它使用的本地缓存进行通讯,这只是dubbo健壮性的一种体现。
- 监控中心宕掉不影响使用,只是丢失部分采样数据
- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
RPC和HTTP
Remote Procedure Call(远程过程调用),是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程。
超文本传输协议,是一种应用层协议。规定了网络传输的请求格式、响应格式、资源定位和操作的方式等。但是底层采用什么网络传输协议,并没有规定,不过现在都是采用TCP协议作为底层传输协议。
- 速度来看,RPC要比http更快,虽然底层都是TCP,但是http协议的信息往往比较臃肿,不过可以采用gzip压缩。
- 难度来看,RPC实现较为复杂,http相对比较简单
- 灵活性来看,http更胜一筹,因为它不关心实现细节,跨平台、跨语言。
两者都有不同的使用场景:
- 如果对效率要求更高,并且开发过程使用统一的技术栈,那么用RPC还是不错的。
- 如果需要更加灵活,跨语言、跨平台,显然http更合适
如何设计一个rpc
- 上来你的服务就得去注册中心注册吧,你是不是得有个注册中心,保留各个服务的信心,可以用zookeeper来做。
- 然后你的消费者需要去注册中心拿对应的服务信息吧,对吧,而且每个服务可能会存在于多台机器上
- 接着你就该发起一次请求了,咋发起?蒙圈了是吧。当然是基于动态代理了,你面向接口获取到一个动态代理,这个动态代理就是接口在本地的一个代理,然后这个代理会找到服务对应的机器地址
- 然后找哪个机器发送请求?那肯定得有个负载均衡算法了,比如最简单的可以随机轮询是不是
- 接着找到一台机器,就可以跟他发送请求了,第一个问题咋发送?你可以说用netty了,nio方式;第二个问题发送啥格式数据?你可以说用hessian序列化协议了,或者是别的,对吧。然后请求过去了。。
- 服务器那边一样的,需要针对你自己的服务生成一个动态代理,监听某个网络端口了,然后代理你本地的服务代码。接收到请求的时候,就调用对应的服务代码



