倒排索引
搜索的核心需求是全文检索,全文检索简单来说就是要在大量文档中找到包含某个单词出现的位置,在传统关系型数据库中,数据检索只能通过 like 来实现。
这种实现方式实际会存在很多问题:
- 无法使用数据库索引,需要全表扫描,性能差
- 搜索效果差,只能首尾位模糊匹配,无法实现复杂的搜索需求
- 无法得到文档与搜索条件的相关性
搜索的核心目标实际上是保证搜索的效果和性能,为了高效的实现全文检索,我们可以通过倒排索引来解决。
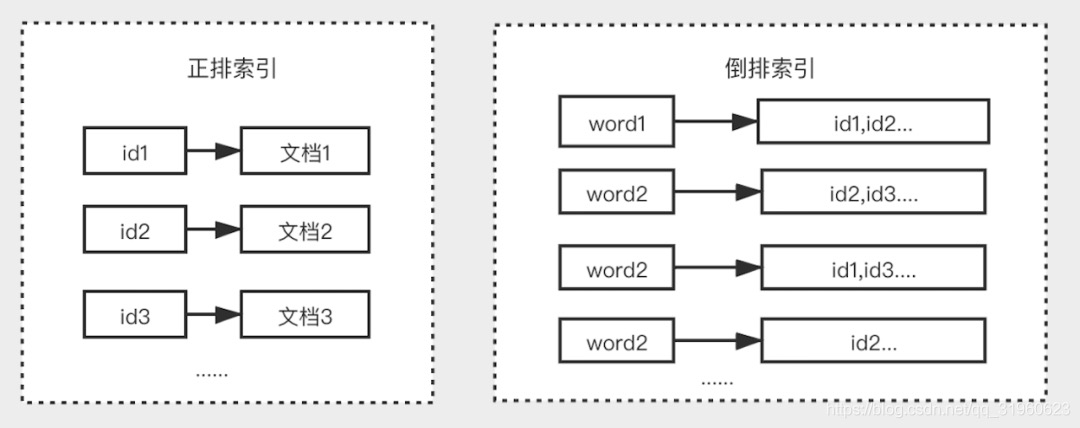
倒排索引是区别于正排索引的概念:
- 正排索引:是以文档对象的唯一 ID 作为索引,以文档内容作为记录。
- 倒排索引:Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录。
但是只是这样是远远不够的,世界上的语言种类特别多,每搜索一个单词,就都要全局遍历,效率特别低。这时候就需要用到了排序,以便采用二分查找等方式提高遍历效率,在这里 lucene 采用了跳表的数据结构,这就是Term Dictionary,另一方面,光使用排序还会导致磁盘IO速度过慢(因为数据都放在磁盘中),如果将数据放入内存,又会导致内存爆满。
所以,Lucene 的倒排索引,在上面的表格的基础上,在左边增加了一层字典树 term index,它不存储所有的单词,只存储单词前缀,通过字典书找到单词所在的块,也就是单词的大概位置,再在块里二分查找,找到对应的单词,再找到单词对应的文档列表。
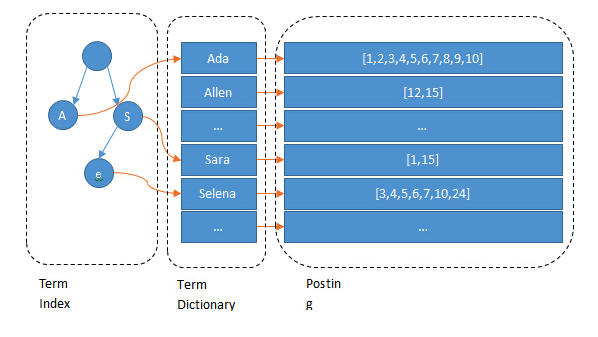
另外,为了进一步节省内存,Lucene 还用了 FST(Finite State Transducers)对 Term Index 做进一步压缩,term index 在内存中是以FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary 在磁盘上是以分 block 的方式保存的,一个block 内部利用公共前缀压缩,比如都是 Ab 开头的单词就可以把 Ab 省去。这样 term dictionary 可以比 b-tree 更节约磁盘空间。



