多字段特性
厂商名字直接实现精确匹配
- 增加一个keyword字段
使用不同的analyzer
- 不同语言
- 拼音字段的搜索
- 支持为搜索和索引指定不同的analyzer
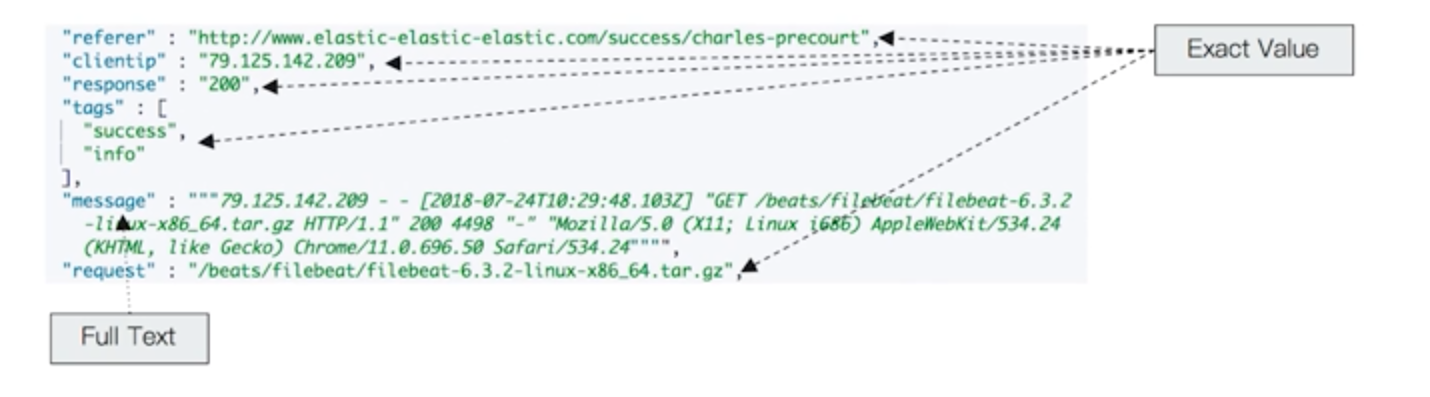
Exact Values v.s Full Text
Exact Values : 包括数字、日期、具体的一个字符串(“Apple Store”)
es 中的keyword
Full Text: 全文本,非结构化的文本数据
- es 中的 text
自定义分词
当Elasticsearch 自带的分词器无法满足时,可以自定义分词,通过自组合不同的组件实现
Character Filters
在Tokenizer之前对文本进行处理,例如增加删除及替换字符可以配置多个Character Filter。会影响Tokenizer的position和offset的信息
自带的Character Filer
HTML strip :去除html标签
POST _analyze { "tokenizer": "keyword", "char_filter": ["html_strip"], "text":"<b>hello word</b>" }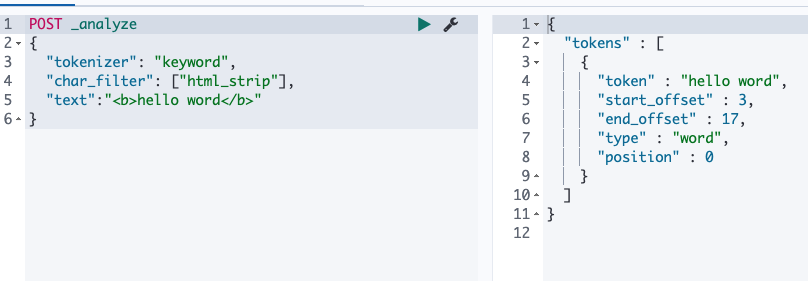
Mapping : 字符串替换
POST _analyze { "tokenizer": "keyword", "char_filter": [ { "type":"mapping", "mappings":["- => _"] } ], "text":"123-213-23-sd-324-df" }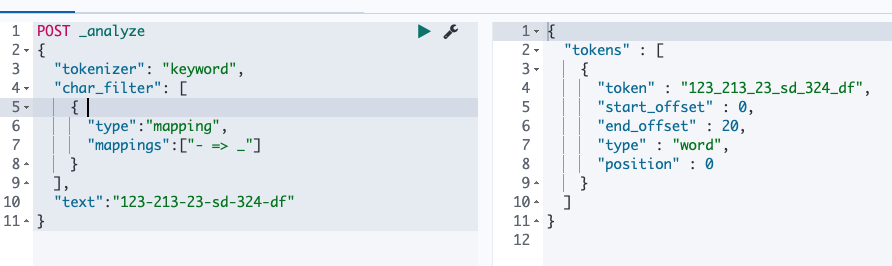
Pattern replace : 正则匹配替换
GET _analyze { "tokenizer": "standard", "char_filter": [ { "type" : "pattern_replace", "pattern" : "http://(.*)", "replacement" : "$1" } ], "text" : "http://www.elastic.co" }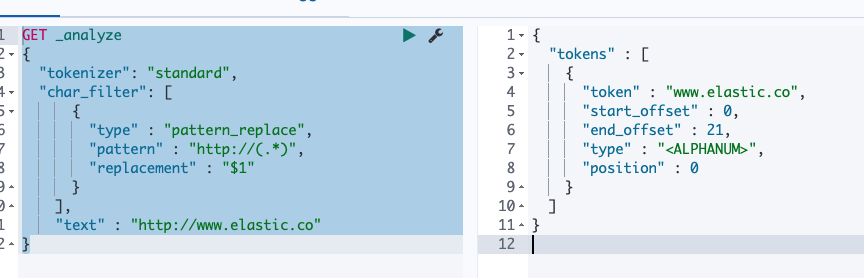
Tokeizer
将原始的文本按照一定的规则,切分为词。
Elasticsearch 内置的Tokenizers
Whitespace / standard / uax_url_email / pattern / keyword /path_hieracrchy
举例:
- whitespace
POST _analyze
{
"tokenizer": "whitespace",
"filter": ["stop"],
"text": "The rain in Spain falls mainly on the plain"
}- path_hieracrchy
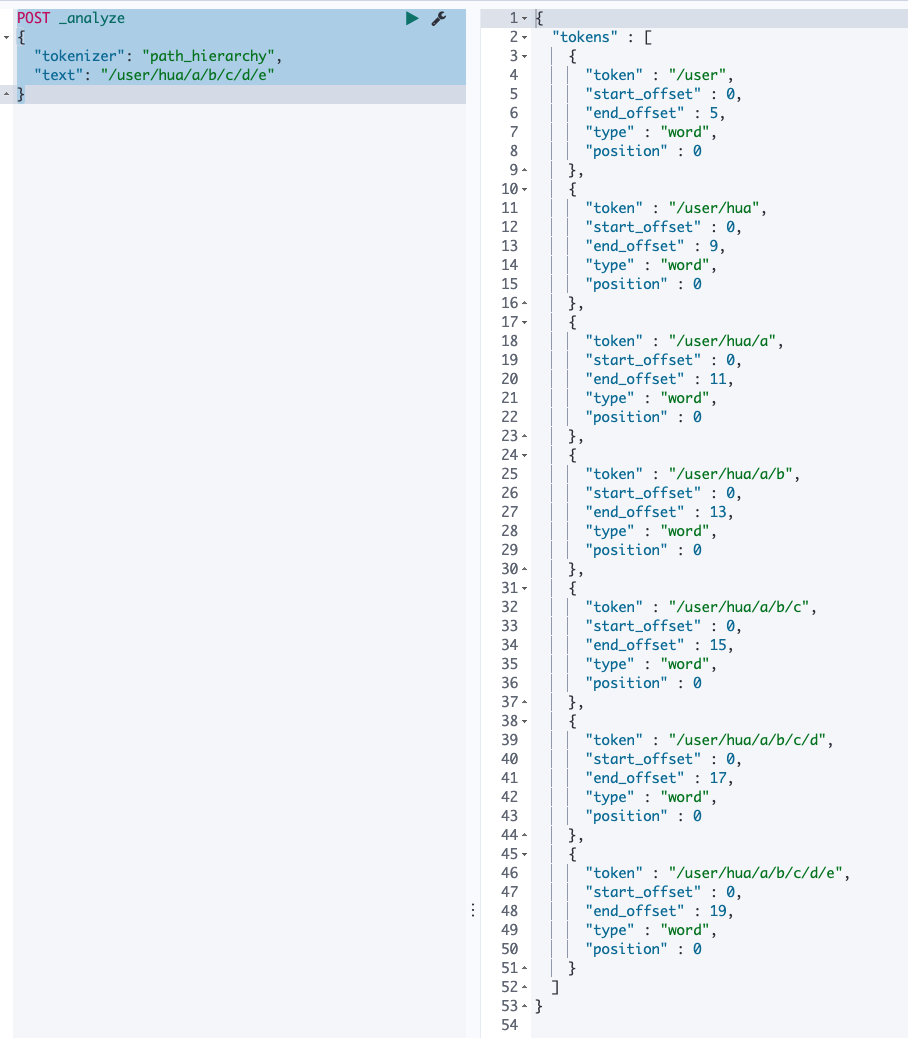
POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/user/hua/a/b/c/d/e"
}
- 可以用java开发插件,实现自己的tokenizer
Token Filters
将tokenizer输出的单词,进行增加,修改,删除。
自带的 token Filters
lowercase / stop /synonym
设置一个 Custom Analyzer
PUT t_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer":"standard",
"char_filter":"my_char_filter"
}
},
"char_filter": {
"my_char_filter":{
"type":"mapping",
"mappings":[
":)=>happy",
":(=>sad"
]
}
}
}
}
}


