public static void main(String[] args) {
UserProtos.User user=UserProtos.User.newBuilder().
setAge(300).setName("abc").build();
byte[] bytes=user.toByteArray();
for(byte bt:bytes){
System.out.print(bt+" ");
}
}
序列化出来的数字基本看不懂,但是序列化以后的数据确实很小,那我们接 下来去了解一下底层的原理
正常来说,要达到最小的序列化结果,一定会用到压缩的技术,而 protobuf 里面用到了两种 压缩算法,一种是 varint,另一种是 zigzag
存储格式
protobuf 采用 T-L-V 作为存储方式
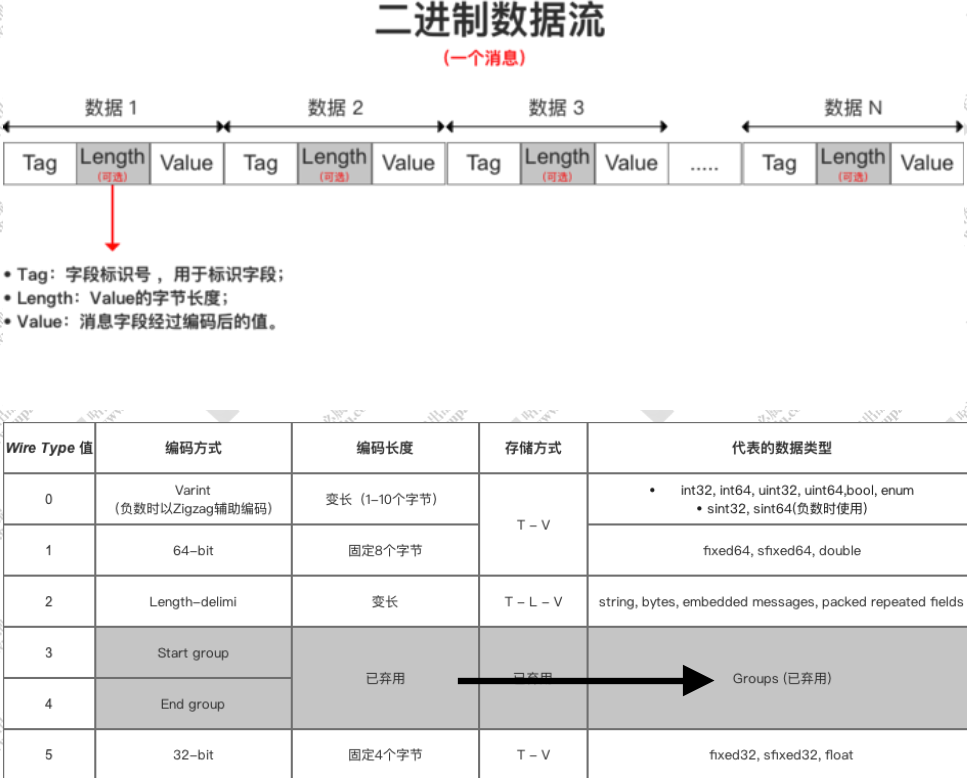
tag 的计算方式是 field_number(当前字段的编号) << 3 | wire_type
比如Mic的字段编号是1 ,类型wire_type的值为 2 所以 : 1<<3|2=10
age=300 的字段编号是 2,类型 wire_type 的值是 0, 所以 : 2<<3|0 =16
负数的存储
在计算机中,负数会被表示为很大的整数,因为计算机定义负数符号位为数字的最高位,所 以如果采用 varint 编码表示一个负数,那么一定需要 5 个比特位。所以在 protobuf 中通过 sint32/sint64 类型来表示负数,负数的处理形式是先采用 zigzag 编码(把符号数转化为无符 号数),在采用 varint 编码。
sint32:(n << 1) ^ (n >> 31)
sint64:(n << 1) ^ (n >> 63)
比如存储一个(-300)的值 -300
原码:0001 0010 1100
取反:1110 1101 0011
加 1 :1110 1101 0100
n<<1: 整体左移一位,右边补 0 -> 1101 1010 1000
n>>31: 整体右移 31 位,左边补 1 -> 1111 1111 1111
n<<1 ^ n >>31
1101 1010 1000 ^ 1111 1111 1111 = 0010 0101 0111
十进制: 0010 0101 0111 = 599
varint 算法: 从右往做,选取 7 位,高位补 1/0(取决于字节数) 得到两个字节
1101 0111 0000 0100
-41 、 4
总结:
Protocol Buffer 的性能好,主要体现在 序列化后的数据体积小 & 序列化速度快,最终使得 传输效率高,其原因如下:
序列化速度快的原因:
a. 编码 / 解码 方式简单(只需要简单的数学运算 = 位移等等)
b. 采用 Protocol Buffer 自身的框架代码 和 编译器 共同完成
序列化后的数据量体积小(即数据压缩效果好)的原因:
a. 采用了独特的编码方式,如 Varint、Zigzag 编码方式等等
b. 采用 T - L - V 的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑



